
朴素贝叶斯算法(Naive Bayes)是机器学习中常见的基本算法之一,主要用来做分类任务的。它是基于贝叶斯定理与条件独立性假设的分类方法。对于给定的训练数据集,首先基于特征条件独立性假设学习输入/输出的联合概率分布,然后基于此模型,对于给定的输入 x 利用贝叶斯定理求出后验概率最大的输出 y。由此可知:1. 该算法的理论核心是贝叶斯定理;2. 它是基于条件独立性假设这个强假设之下的,这也是该算法为什么称为 “朴素” 的原因。
条件概率公式
首先来复习下条件概率公式~
条件概率 P(B|A) 表示已知事件A发生的情况下事件B发生的概率。用图形表示就是这样:
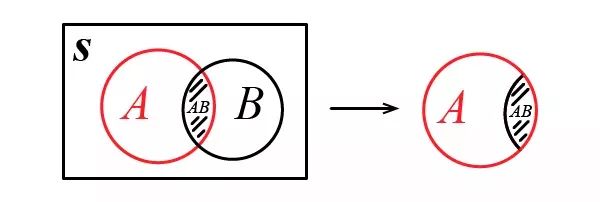

A 发生的条件下 B 发生的情况就是 AB 发生,所以条件概率 P(B|A) 就是 AB 在 A 中所占的比例。样本空间 S,如果设其面积为1,那么(左侧图中)事件 A 和事件 AB 的面积在数值上就等于它们的概率 P(A), P(AB) ,则:
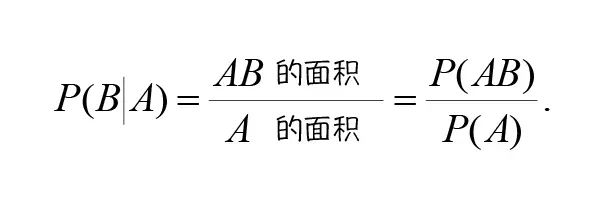
所以可得:
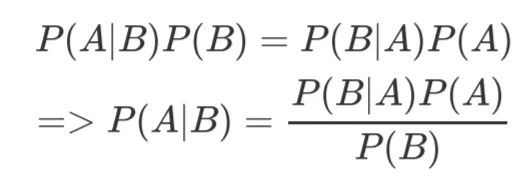
病人分类的例子
接下来,以一个简单的例子来说明贝叶斯分类器。某个医院早上收了六个门诊病人,如下图所示:

现在又来了第七个病人,是一个打喷嚏的建筑工人。请问他患上感冒的概率有多大?
根据条件概率公式:

可得:

假定”打喷嚏”和”建筑工人”这两个特征是独立的,因此,上面的等式就变成了:

计算可得,这个打喷嚏的建筑工人,有66%的概率是得了感冒。

同理,可以计算这个病人患上过敏或脑震荡的概率。比较这几个概率,就可以知道他最可能得什么病。
这就是贝叶斯分类器的基本方法:在统计资料的基础上,依据某些特征,计算各个类别的概率,从而实现分类。
朴素贝叶斯分类器的公式
假设某个体有 n 项特征(Feature),分别为 F1、F2、…、Fn。现有 m 个类别(Category),分别为C1、C2、…、Cm。贝叶斯分类器就是计算出概率最大的那个分类,也就是求下面这个算式的最大值:

由于 P(F1F2…Fn) 对于所有的类别都是相同的,可以省略,问题就变成了求的最大值:

朴素贝叶斯分类器则是更进一步,假设所有特征都彼此独立,因此:

上式等号右边的每一项,都可以从统计资料中得到,由此就可以计算出每个类别对应的概率,从而找出最大概率的那个类。
虽然”所有特征彼此独立”这个假设,在现实中不太可能成立,但是它可以大大简化计算,而且有研究表明对分类结果的准确性影响不大。
使用朴素贝叶斯进行文档分类
以《机器学习实战》一书上的文档分类为例,使用 Python 编写贝叶斯分类器进行文档的自动分类。
首先,我们需要把句子进行拆分,变成单词向量或者词条向量。再考虑所有文档中出现的单词,纳入词汇表,然后将每一篇文档转换为词汇表上的向量。简单起见,我们先假设已经将本文切分完毕,存放到列表中,并对词汇向量进行分类标注。
1. 创建实验数据集
def loadDataSet():
dataSet=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] # 切分好的词条
classVec = [0,1,0,1,0,1] # 类别标签向量,1 代表侮辱性词汇,0 代表非侮辱性词汇
return dataSet,classVec
dataSet,classVec = loadDataSet()
生成 6 句话,其中 3 句带有侮辱性词汇。
2. 生成词汇表
def createVocabList(dataSet):
vocabSet = set() # 创建一个空的元组
for doc in dataSet: # 遍历 dataSet 中的每一条言论
vocabSet = vocabSet | set(doc) # 取并集
vocabList = list(vocabSet)
return vocabList
vocabList = createVocabList(dataSet)
print(vocabList)
['park', 'worthless', 'stop', 'flea', 'quit', 'not', 'dog', 'help', 'him', 'maybe', 'posting', 'steak', 'buying', 'mr', 'to', 'garbage', 'so', 'how', 'licks', 'please', 'my', 'is', 'cute', 'I', 'has', 'stupid', 'food', 'problems', 'ate', 'dalmation', 'take', 'love']
然后,把所有句子中的单词提取成一个词汇表。先用set()对句子中的单词去重,再使用操作符|求两个集合的并集,即可得到所有句子中的单词的一个集合。
3. 词汇表到向量的转化
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0] * len(vocabList) # 创建一个其中所含元素都为 0 的向量
for word in inputSet: # 遍历每个词条
if word in vocabList: # 如果词条存在于词汇表中,则变为 1
returnVec[vocabList.index(word)] = 1
else:
print(f" {word} is not in my Vocabulary!" )
return returnVec #返回文档向量
输入参数为词汇表及某个文档,输出的是文档向量,向量的每一元素为 1 或 0,分别表示词汇表中的单词在输入文档中是否出现。函数首先会创建一个和词汇表等长的向量,并将其元素都设置为 0。接着,遍历文档中的所有单词,如果出现了词汇表中的单词,则将输出的文档向量中的对应值设为 1。
4. 生成所有词条向量列表
def get_trainMat(dataSet):
trainMat = [] #初始化向量列表
vocabList = createVocabList(dataSet) # 生成词汇表
for inputSet in dataSet: # 遍历样本词条中的每一条样本
returnVec=setOfWords2Vec(vocabList, inputSet) # 将当前词条向量化
trainMat.append(returnVec) # 追加到向量列表中
return trainMat
将上面写的三个函数包装下,来生成所有词条的向量列表。
5. 构建朴素贝叶斯分类器的训练函数
之前提到朴素贝叶斯分类器可以用下面的公式来计算概率,计算出每个类别对应的概率,从而进行预测。
所以代码的逻辑就是,计算每个类别的文档数目,对每篇训练文档的每个类别分别计算条件概率。
def trainNB(trainMat,classVec):
n = len(trainMat) # 计算训练的文档数目
m = len(trainMat[0]) # 计算每篇文档的词条数,其实就是词汇表的长度
pAb = sum(classVec)/n # 文档属于侮辱类的概率,因为侮辱类标记为 1
p0Num = np.zeros(m) # 词条出现数初始化为 0
p1Num = np.zeros(m) # 词条出现数初始化为0
p0Denom = 0 # 分母初始化为 0
p1Denom = 0 # 分母初始化为 0
for i in range(n): # 遍历每一个文档
if classVec[i] == 1: # 统计属于侮辱类的条件概率所需的数据
p1Num += trainMat[i]
p1Denom += sum(trainMat[i])
else: # 统计属于非侮辱类的条件概率所需的数据
p0Num += trainMat[i]
p0Denom += sum(trainMat[i])
p1V = p1Num/p1Denom
p0V = p0Num/p0Denom
return p0V,p1V,pAb # 返回属于非侮辱类,侮辱类和文档属于侮辱类的概率
构造函数进行朴素贝叶斯分类器分类。使用reduce()函数配合lambda匿名函数实现对应元素相乘的功能,因为是二分类问题,所以文档属于非侮辱类的概率就是(1 - pAb)。
from functools import reduce
def classifyNB(vec2Classify, p0V, p1V, pAb):
p1 = reduce(lambda x,y:x*y, vec2Classify * p1V) * pAb # 对应元素相乘
p0 = reduce(lambda x,y:x*y, vec2Classify * p0V) * (1 - pAb)
print('p0:',p0)
print('p1:',p1)
if p1 > p0:
return 1
else:
return 0
6. 测试朴素贝叶斯分类器
最后,我们来测试下这个分类器:
def testingNB(testVec):
dataSet,classVec = loadDataSet() #创建实验样本
vocabList = createVocabList(dataSet) #创建词汇表
trainMat= get_trainMat(dataSet) #将实验样本向量化
p0V,p1V,pAb = trainNB(trainMat,classVec) #训练朴素贝叶斯分类器
thisone = setOfWords2Vec(vocabList, testVec) #测试样本向量化
if classifyNB(thisone,p0V,p1V,pAb):
print(testVec,'属于侮辱类') #执行分类并打印分类结果
else:
print(testVec,'属于非侮辱类') #执行分类并打印分类结果
#测试样本1
testVec1 = ['love', 'my', 'dalmation']
testingNB(testVec1)
['love', 'my', 'dalmation'] 属于非侮辱类
testVec2 = ['stupid', 'garbage']
testingNB(testVec2)
p0: 0.0
p1: 0.0
['stupid', 'garbage'] 属于非侮辱类
显而易见,对于第二个测试数据,分类器无法正确进行分类,这是为什么呢?
7. 朴素贝叶斯改进之拉普拉斯平滑
由朴素贝叶斯分类器的公式可知,利用贝叶斯分类器对文档进行分类时,要计算多个概率的乘积以获得文档属于某个类别的概率。如果其中有一个概率值为 0,那么最后的成绩也为 0。显然,这样是不合理的,为了降低这种影响,可以将所有词的出现数初始化为 1,并将分母初始化为 2。这种做法就叫做拉普拉斯平滑 (Laplace Smoothing)又被称为加 1 平滑,是比较常用的平滑方法,它就是为了解决 0 概率问题。
另外一个遇到的问题就是下溢出,这是由于太多很小的数相乘造成的。我们在计算乘积时,由于大部分因子都很小,所以程序会下溢或者得不到正确答案。为了解决这个问题,对乘积结果取自然对数。通过求对数可以避免下溢出或者浮点数舍入导致的错误。同时,采用自然对数进行处理不会有任何损失。
修改代码如下:
def trainNB(trainMat,classVec):
n = len(trainMat) #计算训练的文档数目
m = len(trainMat[0]) #计算每篇文档的词条数
pAb = sum(classVec)/n #文档属于侮辱类的概率
p0Num = np.ones(m) #词条出现数初始化为1
p1Num = np.ones(m) #词条出现数初始化为1
p0Denom = 2 #分母初始化为2
p1Denom = 2 #分母初始化为2
for i in range(n): #遍历每一个文档
if classVec[i] == 1: #统计属于侮辱类的条件概率所需的数据
p1Num += trainMat[i]
p1Denom += sum(trainMat[i])
else: #统计属于非侮辱类的条件概率所需的数据
p0Num += trainMat[i]
p0Denom += sum(trainMat[i])
p1V = np.log(p1Num/p1Denom)
p0V = np.log(p0Num/p0Denom)
return p0V,p1V,pAb #返回属于非侮辱类,侮辱类和文档属于侮辱类的概率
查看代码运行结果:
p0V,p1V,pAb=trainNB(trainMat,classVec)
def classifyNB(vec2Classify, p0V, p1V, pAb):
p1 = sum(vec2Classify * p1V) + np.log(pAb) #对应元素相乘
p0 = sum(vec2Classify * p0V) + np.log(1- pAb) #对应元素相乘
if p1 > p0:
return 1
else:
return 0
测试代码运行结果:
#测试样本1
testVec1 = ['love', 'my', 'dalmation']
testingNB(testVec1)
['love', 'my', 'dalmation'] 属于非侮辱类
#测试样本2
testVec2 = ['stupid', 'garbage']
testingNB(testVec2)
['stupid', 'garbage'] 属于侮辱类
现在分类器已经构建好啦~
朴素贝叶斯的优缺点
-
优点:
-
朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
-
对小规模的数据表现很好,能个处理多分类任务,适合增量式训练,尤其是数据量超出内存时,我们可以一批批的去增量训练。
-
对缺失数据不太敏感,算法也比较简单,常用于文本分类。
-
缺点:
-
理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
-
需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
-
由于我们是通过先验和数据来决定后验的概率从而决定分类,所以分类决策存在一定的错误率。
-
对输入数据的表达形式很敏感。
本文来自生信菜鸟团,如有不妥请联系删除,仅供交流学习。
