
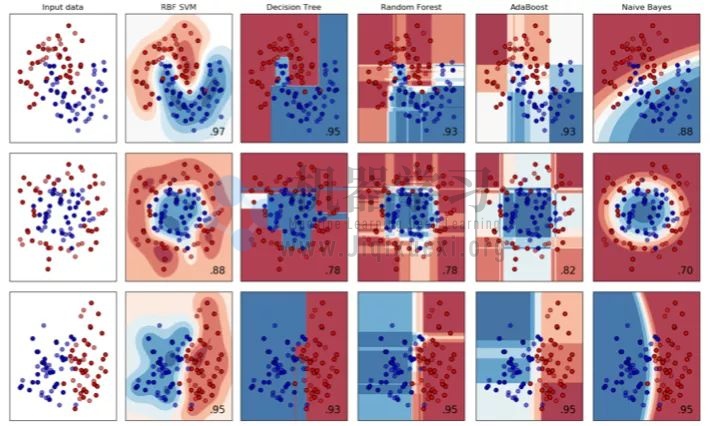
支持向量机(SVM,也称为支持向量网络),是机器学习中获得关注最多的算法。从算法的功能来看,SVM 包括以下一些功能:


从分类效力来讲,SVM在无论线性还是非线性分类中,都十分出色:
什么是 SVM?
首先让我们从一个简单的故事来了解「SVM」吧~
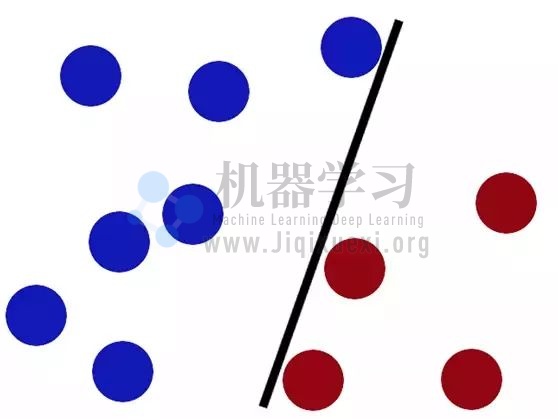
现在桌子上有一些杂乱的「小球」我们想要将他们分开:

我们可以放一根棒棒上去~是不是看起来还行,小棍将蓝色球和红色球分开。
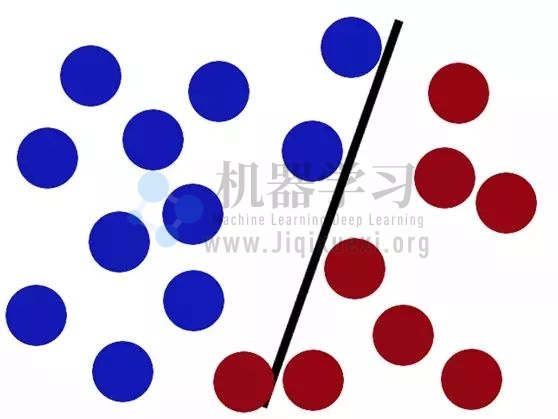
但这时,又有个人把一颗红色的小球放在了棍子的另一边,这样就有一个球似乎落在了错误的一侧,我们可能需要调整棒棒:
所谓,SVM 就是要将棒棒放置到最佳位置上,使得两侧都有尽可能大的间隔:
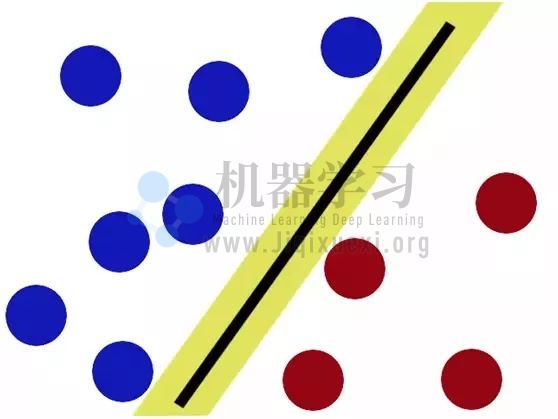
现在即使再有人捣乱,棒棒也能把两种颜色的小球分开:
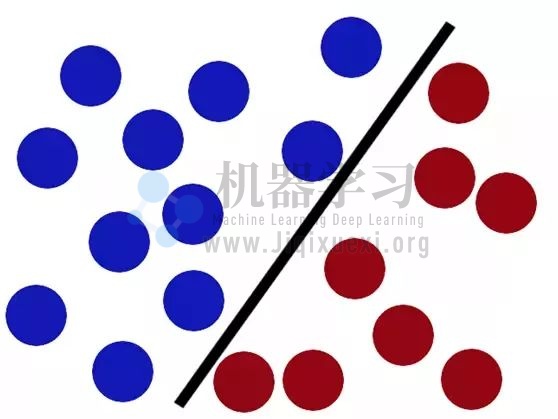
但要是小球是这样摆放怎么办?好像没有任何一根直的棒棒可以把两种小球分开:
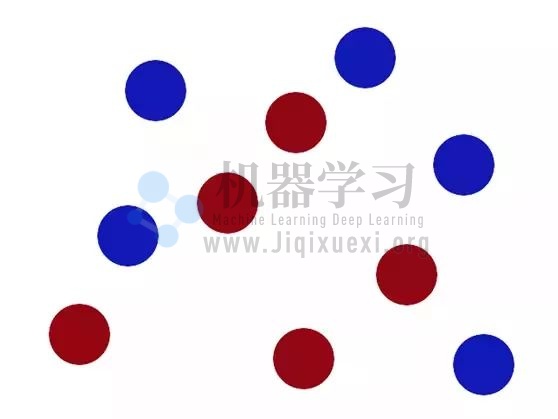
那就使出你三成内力拍向桌子,将小球震向空中!凭借你水果忍者的技术,用一张纸切到小球中间!
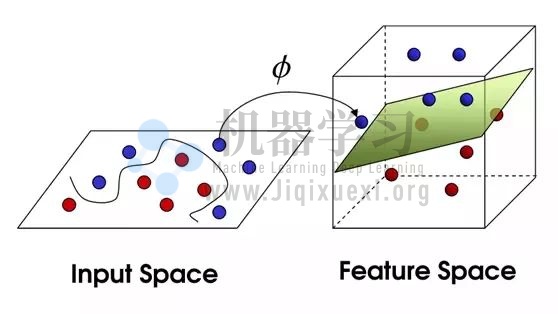
现在~特征空间出现了,而在别人的角度看来小球似乎被一条曲线完美分隔:
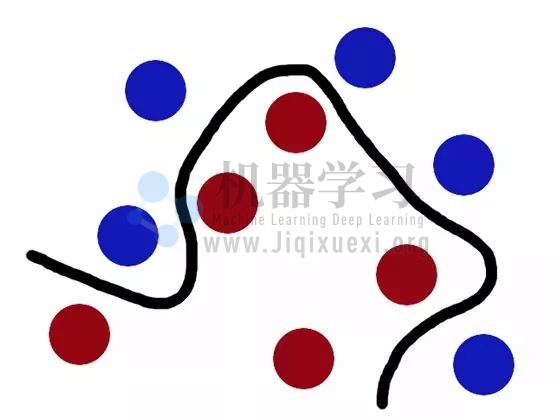
数据科学家们就把这些小球称为「数据」、棒棒称为「分类器」、找到最大间隔的过程称为「优化」、拍桌子叫「核函数kernelling」、那张纸叫「超平面」。
总结一下就是说,当一个分类问题是线性可分的时候,我们只需用一根棒就可以将小球分开,棒棒最佳的位置就是让两种小球离棒的距离最远,寻找这个最大间隔的过程就是「优化」。但现实中,一般的数据往往是线性不可分的,这个时候我们就需要将小球拍起「核函数」,用一张纸「超平面」在空间中将小球分开。如果数据是 N 维的,那么超平面就是 N-1 维的。比较下之前所学的内容,其实 logistic 模型找的超平面,是尽量让所有点都远离它,而 SVM 寻找的超平面,是只让最靠近中间分割线的那些点尽量远离,即只用到那些「支持向量 support vector」的样本——所以叫「支持向量机」。
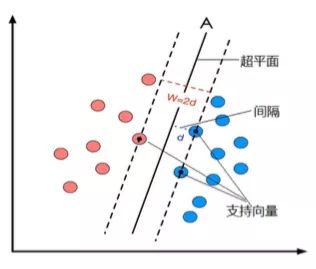
把一个数据集正确分开的超平面可能有多个,而具有「最大间隔」的超平面就是 SVM 所要找的最优解。最靠近超平面的样本点即为「支持向量」。支持向量到超平面的距离称为「间隔 margin」。
核函数
在上面的例子中,我们通过将空间巧妙地映射到更高维度来分类非线性数据。然而事实证明,这种转换可能会带来很大的计算成本:可能会出现很多新的维度,每一个都可能带来复杂的计算。为数据集中的所有向量做这种操作会带来大量的工作,所以寻找一个更简单的方法非常重要。
还好,我们已经找到了一些诀窍:SVM 其实并不需要真正的向量,它可以用它们的数量积(点积)来进行分类。这意味着我们可以避免耗费计算资源的境地了。我们需要这样做:
-
想象一个我们需要的新空间:
-
z = x² + y²
-
找到新空间中点积的形式:
-
a · b = xa· xb + ya· yb + za· zb
-
a · b = xa· xb + ya· yb + (xa² + ya²) · (xb² + yb²)
-
让 SVM 处理新的点积结果——这就是核函数
这就是核函数的技巧,它可以减少大量的计算资源需求。通常,内核是线性的,所以我们得到了一个线性分类器。但如果使用非线性内核,我们可以在完全不改变数据的情况下得到一个非线性分类器:我们只需改变点积为我们想要的空间,SVM 就会对它忠实地进行分类。注意,核函数技巧实际上并不是 SVM 的一部分。它可以与其他线性分类器共同使用,如逻辑回归等。支持向量机只负责找到决策边界。
以上就是支持向量机的基础。总结来说就是:
-
支持向量机能让你分类线性可分的数据;
-
如果线性不可分,你可以使用 kernel 技巧。
相比于神经网络这样更先进的算法,支持向量机有两大主要优势:更高的速度、用更少的样本(千以内)取得更好的表现。这使得该算法非常适合文本分类问题。
关于数学推导 SVM 我在下周可能会提及一些,因为确实有些复杂。。。我还没有参悟透 QAQ,自己挖的坑含着泪也得填上。。。
在 B 站上看到大佬白板推导 SVM,真是「太强了」,思路清晰易懂,推荐给大家:av28186618
本文来自生信菜鸟团,如有不妥请联系删除,仅供交流学习。
