


1. kNN 算法原理
k-近邻算法(k-Nearest Neighbour algorithm)的工作原理:给定一个已知标签类别的训练数据集,输入没有标签的新数据后,在训练数据集中找到与新数据最邻近的 k 个实例,如果这 k 个实例的多数属于某个类别,那么新数据就属于这个类别。即由那些离新数据最近的 k 个实例来投票决定新数据归为哪一类。
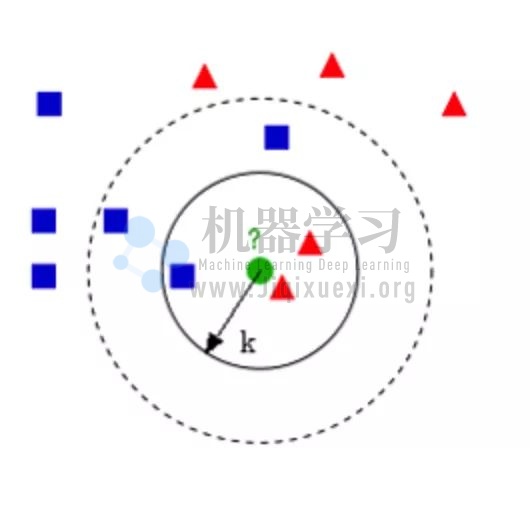
比如,有红色三角形和蓝色方块两种类型,现在想要判断绿色的圆点属于那种类别:
若 k=3,绿色圆点属于红色三角类别(距离绿色圆点最近的是 2 个红色三角和 1 个蓝色方块,少数服从多数,继而判定绿色圆点属于红色三角);若 k=5,绿色圆点属于蓝色方块类别。
2. kNN 算法的流程
-
计算已知类别数据集中的点与当前点之间的距离;
-
按照距离递增次序排序;
-
选取与当前点距离最小的 k 个点;
-
确定前 k 个点所在类别的出现频率;
-
返回前 k 个点出现频率最高的类别作为当前点的预测类别。
3. kNN 的基本要素
由上述的流程可知,对于一个确定的训练集,只要确定了距离度量、k值和分类决策规则,就能对任何一个新的实例,确定它的分类。
3.1 距离度量
距离度量是描述特征空间中两个实例的距离,也是这两个实例的相似程度。在 n 维实数向量空间中,我们主要使用的距离度量方式是欧式距离,但也可以使用更加一般的 Minkowski 距离。
3.1.1 欧氏距离
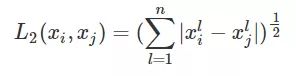
3.1.2 曼哈顿距离
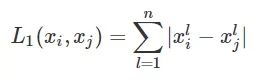
3.1.3 闵可夫斯基距离
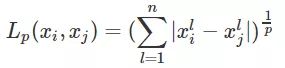
3.2 k 值的选择
对于k值的选择,一般根据样本的分布,选择一个较小的值,然后通过交叉验证选择一个合适的k值。
-
选择较小的k值,就相当于用较小的领域中的训练实例进行预测,训练误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是泛化误差会增大。换句话说,k值的减小就意味着整体模型变得复杂,容易发生过拟合。
-
选择较大的k值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少泛化误差,但缺点是训练误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误。换句话说,k值的增大就意味着整体的模型变得简单,容易发生欠拟合。
一个极端的例子是 k 等于样本数,则完全没有分类,那么无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的类,模型过于简单。
3.3 分类决策规则
k 近邻法中的分类决策规则往往是多数表决,即由输入实例的k个邻近的训练实例中的多数类决定输入实例的类。
4. kNN 算法的 Python 实现
有人曾经统计过很多电影的打斗镜头和接吻镜头,下图显示了 6 部电影的打斗和接吻镜头数。假如有一部未看过的电影,如何确定它是爱情片还是动作片呢?我们可以使用 kNN 来解决这个问题。
4.1 算法实现
4.1.1 构建已经分类好的原始数据集
import pandas as pd
import seaborn as sns
%matplotlib inline
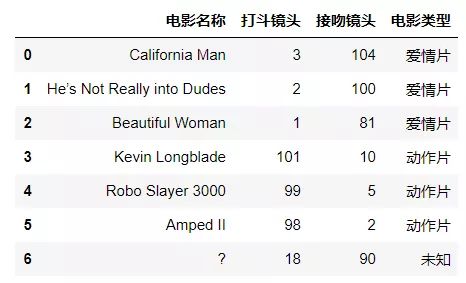
data = {'电影名称':['California Man','He’s Not Really into Dudes','Beautiful Woman','Kevin Longblade','Robo Slayer 3000','Amped II','?'],
'打斗镜头':[3,2,1,101,99,98,18],
'接吻镜头':[104,100,81,10,5,2,90],
'电影类型':['爱情片','爱情片','爱情片','动作片','动作片','动作片','未知']}
movie_data = pd.DataFrame(data)
movie_data
sns.lmplot('打斗镜头','接吻镜头',movie_data,hue='电影类型', fit_reg=False)
<seaborn.axisgrid.FacetGrid at 0x193aaee9fd0>
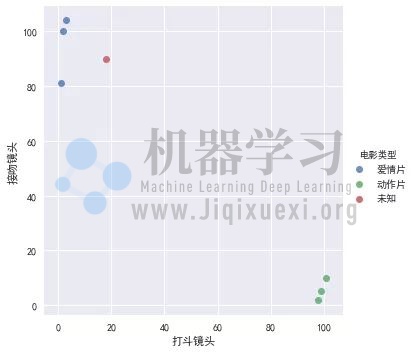
我们可以从散点图中大致推断,这个未知电影有可能是爱情片,因为看起来它距离已知的三个爱情片的点更近一点。那么,具体是如何来度量距离的呢?这个例子中我们使用欧氏距离来衡量。
4.1.2 计算已知类别数据集中的点与当前点之间的距离
new_data=list(movie_data.loc[6][1:3])
dist = list((((movie_data.iloc[:6,1:3]-new_data)**2).sum(1))**0.5)
# .iloc:根据标签的所在位置,从 0 开始计数,选取列
# loc:根据 DataFrame 的具体标签选取列
dist
[42.5440947723653,
39.66106403010388,
26.92582403567252,
95.80187889597991,
97.30878685915265,
98.49365461794989]
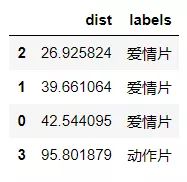
4.1.3 将距离升序排列,然后选取距离最小的k个点
dist_l = pd.DataFrame({'dist':dist, 'labels':movie_data.iloc[:6,3]})
dr = dist_l.sort_values(by='dist')[:4]
dr
4.1.4 确定前k个点所在类别的出现频率
re = dr.loc[:,'labels'].value_counts()
re
爱情片 3
动作片 1
Name: labels, dtype: int64
4.1.5 选择频率最高的类别作为当前点的预测类别
result = []
result.append(re.index[0])
result
['爱情片']
4.2 封装函数
import pandas as pd
def classify0(inX, dataSet, k):
result = []
dist = list((((dataSet.iloc[:,1:3]-inX)**2).sum(1))**0.5)
dist_l = pd.DataFrame({'dist':dist, 'labels':dataSet.iloc[:,3]})
dr = dist_l.sort_values(by='dist')[:k]
re = dr.loc[:,'labels'].value_counts()
result.append(re.index[0])
return result
classify0(new_data, movie_data[], 4)
['爱情片']
4.3 sklearn 实现
Scikit-learn 是专门面向机器学习的 Python 开源框架,它实现了各种成熟的算法,并且易于安装与使用。KNeighborsClassifier 在 scikit-learn 在 sklearn.neighbors 包之中。KNeighborsClassifier 使用很简单,三步:
-
创建 KNeighborsClassifier 对象;
-
调用 fit 函数;
-
调用predict函数进行预测。
from sklearn.neighbors import KNeighborsClassifier
X = movie_data.iloc[:6,1:3]
y = movie_data.iloc[:6,3]
neigh=KNeighborsClassifier(n_neighbors=4)
neigh.fit(X,y)
print(neigh.predict([[18,90]]))
['爱情片']
5. 优缺点
-
优点:简单,易于理解,无需建模与训练,易于实现;适合对稀有事件进行分类;适合与多分类问题,例如根据基因特征来判断其功能分类,kNN 比 SVM 的表现要好。
-
缺点:惰性算法,内存开销大,对测试样本分类时计算量大,性能较低;可解释性差,无法给出决策树那样的规则。
Reference
-
《机器学习实战》第 2 章 k-近邻算法
-
《统计学习方法》第 3 章 k 近邻法
-
K近邻算法(KNN)
本文来自生信菜鸟团,如有不妥请联系删除,仅供交流学习。
